
Last Updated on agosto 12, 2024 1:06 pm by Laszlo Szabo / NowadAIs | Published on agosto 12, 2024 by Laszlo Szabo / NowadAIs
Adiós a la IA por turnos: hola al modelo lingüístico que escucha mientras habla – Notas clave
- El Listening-While-Speaking Language Model (LSLM) integra la escucha y el habla en tiempo real, eliminando las limitaciones de los sistemas de diálogo por turnos.
- Desarrollado por la Universidad Jiao Tong de Shanghai y ByteDance, LSLM utiliza una arquitectura de doble canal que combina un TTS basado en tokens y un codificador SSL de streaming.
- LSLM gestiona eficazmente las interrupciones y el ruido de fondo, demostrando robustez y sensibilidad en diversos entornos experimentales.
- La estrategia de fusión intermedia optimiza la interacción fusionando los canales de escucha y habla en cada bloque Transformer, lo que garantiza una experiencia de diálogo sin fisuras.
Introducción
En el panorama de la interacción persona-ordenador (HCI), la búsqueda de una comunicación más natural e intuitiva ha sido una fuerza impulsora de los avances tecnológicos. Como forma fundamental de interacción humana, el diálogo ha sido durante mucho tiempo el santo grial de los sistemas de IA conversacional. Los recientes avances en los modelos del lenguaje del habla (SLM) han mejorado indudablemente las capacidades de la IA conversacional basada en el habla, pero estos sistemas han seguido limitados por su naturaleza basada en turnos, careciendo de la capacidad de participar en interacciones ininterrumpidas en tiempo real.
Esta limitación ha suscitado un renovado interés por explorar el modelado dúplex completo (FDM) en los modelos interactivos del lenguaje del habla (iSLM), con investigadores que buscan desbloquear la capacidad por excelencia de interrupción y comunicación fluida de ida y vuelta. En medio de esta búsqueda, ha surgido una nueva innovación: el modelo lingüístico de escucha mientras se habla (Listening-While-Speaking Language Model, LSLM), un sistema integral diseñado para actualizar la forma de conversar entre humanos y máquinas.
Las limitaciones de los sistemas de diálogo por turnos
Los modelos tradicionales de habla y lenguaje se han basado normalmente en un enfoque por turnos, en el que la escucha y el habla se producen en fases aisladas. Esta estructura en silos, que a menudo implica módulos separados de reconocimiento automático del habla (ASR) y de conversión de texto en habla (TTS), ha dado lugar a problemas de latencia inherentes y a una incapacidad para gestionar eficazmente las interrupciones en tiempo real. Modelos notables como SpeechGPT y LauraGPT han ampliado los límites de la IA conversacional, pero siguen limitados a estos paradigmas basados en turnos, sin proporcionar la interacción fluida necesaria para un diálogo humano-ordenador verdaderamente natural.
El nacimiento de LSLM: un puente en la interacción en tiempo real
Reconociendo la necesidad de una experiencia conversacional más fluida y receptiva, un equipo de investigadores de la Universidad Jiao Tong de Shanghai y ByteDance introdujo el modelo de lenguaje de escucha mientras se habla (Listening-While-Speaking Language Model, LSLM). Este modelo pretende superar las limitaciones de los sistemas por turnos integrando las capacidades de escucha y habla en una única arquitectura integral.
El enfoque de doble canal de LSLM
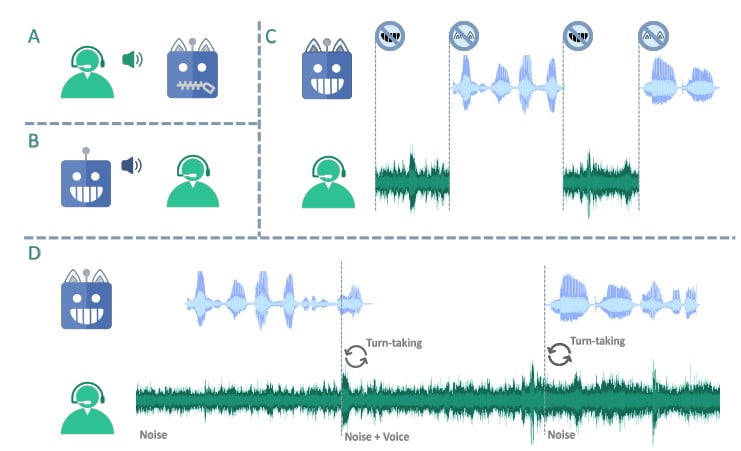
El diseño exclusivo del LSLM gira en torno a su arquitectura de doble canal, que combina un TTS basado sólo en decodificador de tokens para la generación del habla y un codificador de aprendizaje autosupervisado (SSL) para la entrada de audio en tiempo real. Este enfoque permite al modelo fusionar los canales de escucha y habla, lo que le permite detectar la toma de turnos en tiempo real y responder dinámicamente a la entrada del usuario.
El canal del habla: TTS autorregresivo basado en fichas
A diferencia de los modelos anteriores, que se basaban en enfoques autorregresivos y no autorregresivos, el LSLM simplifica el proceso de generación del habla utilizando un sistema TTS basado en fichas. Esta configuración permite al modelo centrarse más en la información semántica, mejorando la claridad y relevancia de sus respuestas y mejorando la interacción en tiempo real al eliminar la necesidad de un amplio preprocesamiento antes de la síntesis del habla.
El canal de escucha: Codificador SSL de streaming
En el canal de escucha, el LSLM emplea un codificador SSL de flujo continuo para procesar las señales de audio entrantes. Este codificador convierte la entrada de audio en incrustaciones continuas, que luego se proyectan en un espacio que puede integrarse perfectamente con los tokens hablados. Esta integración garantiza que el modelo pueda aprovechar la información de ambos canales a lo largo del proceso de generación del habla.
Estrategias de fusión: Equilibrio entre la interacción en tiempo real y la generación del habla
Para optimizar la sinergia entre los canales de escucha y habla, los investigadores estudiaron tres estrategias de fusión: fusión temprana, fusión intermedia y fusión tardía. Tras una cuidadosa evaluación, la fusión intermedia resultó ser la más eficaz, ya que lograba un equilibrio óptimo entre la interacción en tiempo real y la capacidad de generación de voz.
En el método de fusión intermedia, los canales de escucha y habla se fusionan en cada bloque Transformer, lo que permite al modelo aprovechar continuamente la información de ambos canales durante el proceso de generación del habla. Esta integración garantiza que el LSLM pueda manejar las interrupciones sin problemas y mantener un flujo de diálogo coherente y receptivo, adaptándose a las entradas del usuario en tiempo real.
Evaluación del rendimiento de LSLM: Robustez y sensibilidad
Las capacidades del LSLM se pusieron a prueba en dos escenarios experimentales: FDM basado en comandos y FDM basado en voz. En el escenario basado en órdenes, el modelo demostró su robustez frente al ruido de fondo, respondiendo eficazmente a órdenes específicas en medio de un entorno ruidoso. En el escenario basado en la voz, en cambio, se evaluó la sensibilidad del LSLM a las interrupciones de varios interlocutores, mostrando su capacidad para reconocer y adaptarse a nuevas voces e instrucciones.
Los resultados de estos experimentos pusieron de manifiesto el impresionante rendimiento del LSLM, subrayando su potencial para revolucionar el campo de los modelos interactivos de habla y lenguaje. La estrategia de fusión intermedia, en particular, demostró ser un factor crucial para equilibrar las exigencias de la interacción en tiempo real y la generación del habla, ofreciendo una experiencia de usuario fluida y receptiva.
Avanzando en las fronteras de la IA conversacional
El Listening-While-Speaking Language Model (LSLM) representa un avance significativo en el ámbito de los modelos interactivos de habla y lenguaje. Al abordar las limitaciones de los sistemas basados en turnos e introducir una sólida capacidad de interacción en tiempo real, el LSLM allana el camino hacia diálogos más naturales y fluidos entre humanos y ordenadores. Esta investigación pone de relieve la importancia de integrar capacidades full duplex en los SLM, mostrando cómo tales avances pueden mejorar la aplicabilidad de la IA conversacional en escenarios del mundo real.
Conclusiones: Liberar todo el potencial de la IA conversacional
El Listening-While-Speaking Language Model (LSLM) representa un avance transformador en el campo de los modelos interactivos del habla y el lenguaje. Al integrar a la perfección las capacidades de escucha y habla, este diseño supera las limitaciones de los sistemas tradicionales basados en turnos, dando paso a una nueva era de diálogo más natural y fluido entre humanos y ordenadores. A medida que crece la demanda de IA conversacional intuitiva y con capacidad de respuesta, la capacidad del LSLM para facilitar la interacción en tiempo real y gestionar las interrupciones con facilidad lo sitúa como un elemento de cambio en la búsqueda de una comunicación humano-IA realmente fluida.
Descripciones
- Modelado dúplex completo (FDM): Sistema de comunicación en el que ambas partes pueden hablar y escuchar simultáneamente, a diferencia de los modelos por turnos en los que una parte debe esperar a que la otra termine de hablar.
- TTS con decodificador basado en fichas: sistema que utiliza fichas, o bits de datos, para generar el habla, lo que permite a la IA responder con mayor rapidez y precisión al centrarse en el significado en lugar de preprocesar datos extensos.
- Codificador de aprendizaje autosupervisado (SSL): Tipo de IA que procesa entradas de audio de forma continua, convirtiendo los sonidos en datos que el modelo puede comprender y utilizar para interactuar en tiempo real.
- Bloque transformador: Componente de los modelos de IA que ayuda a procesar y comprender el lenguaje centrándose en diferentes partes de los datos de entrada simultáneamente, lo que mejora la velocidad y la precisión.
- Estrategias de fusión: Técnicas utilizadas para integrar datos de diferentes canales en un modelo de IA. Las estrategias de fusión temprana, intermedia y tardía determinan cómo y cuándo se combinan los datos durante el procesamiento para optimizar el rendimiento.
- FDM basado en comandos: configuración experimental en la que el modelo de IA responde a comandos de voz específicos, poniendo a prueba su capacidad para funcionar en medio de ruidos de fondo e interrupciones.
- FDM basado en la voz: un escenario experimental que evalúa la capacidad de la IA para manejar distintas voces e interrupciones, valorando su adaptabilidad a nuevos interlocutores e instrucciones.
Preguntas más frecuentes
- ¿Qué es el Listening-While-Speaking Language Model (LSLM)? El Listening-While-Speaking Language Model (LSLM) es un sistema avanzado de inteligencia artificial diseñado para dialogar en tiempo real integrando las capacidades de escucha y habla. A diferencia de los modelos tradicionales, permite una comunicación fluida de ida y vuelta sin necesidad de tomar turnos.
- ¿Cómo gestiona el LSLM las interrupciones durante las conversaciones? El LSLM utiliza una arquitectura de doble canal con un codificador SSL que procesa continuamente la entrada de audio. Esta configuración le permite reconocer las interrupciones y adaptarse a ellas sin problemas, manteniendo un flujo de diálogo coherente incluso cuando se introducen nuevas voces o comandos.
- ¿Qué hace que la estrategia de fusión intermedia sea eficaz en el LSLM? La estrategia de fusión intermedia combina los canales de escucha y habla en cada bloque Transformer, lo que permite al modelo aprovechar ambos conjuntos de información a lo largo del diálogo. Este enfoque equilibra la interacción en tiempo real con la generación del habla, mejorando la capacidad de respuesta y la coherencia de la IA.
- ¿Cómo gestiona el LSLM el ruido de fondo durante sus operaciones? En entornos experimentales basados en comandos, el LSLM demostró su solidez filtrando eficazmente el ruido de fondo y centrándose en comandos específicos. Sus avanzadas capacidades de procesamiento garantizan respuestas precisas incluso en entornos ruidosos.
- ¿Cuáles son las aplicaciones potenciales del modelo de escucha mientras se habla? El LSLM puede mejorar las interacciones persona-ordenador en diversos campos, como la atención al cliente, los dispositivos domésticos inteligentes y los asistentes virtuales. Su capacidad para manejar diálogos e interrupciones en tiempo real lo hace ideal para escenarios que requieren una comunicación fluida e intuitiva.