
Last Updated on noviembre 25, 2025 1:59 pm by Laszlo Szabo / NowadAIs | Published on noviembre 25, 2025 by Laszlo Szabo / NowadAIs
Vuelven los pesos pesados: Claude Opus 4.5 de Anthropic reclama el trono – Notas clave
- Liderazgo de referencia en codificación: Claude Opus 4.5 ha alcanzado una precisión del 80,9% en SWE-bench Verified, convirtiéndose en el primer modelo en superar el umbral del 80% en esta prueba de referencia de ingeniería de software estándar del sector. Este rendimiento superó tanto al Gemini 3 Pro de Google, con un 76,2%, como al GPT-5.1-Codex-Max especializado de OpenAI, con un 77,9%, estableciendo el modelo como el estado actual de la técnica para la generación automatizada de código y las tareas de depuración.
- Estrategia de precios agresiva: Anthropic redujo el precio de la API en aproximadamente un 67% en comparación con los modelos Opus anteriores, fijando las tarifas en 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida. Esta drástica reducción de precios democratizó el acceso a las capacidades de IA de vanguardia, al tiempo que mantuvo la eficiencia de los tokens, lo que se traduce en un ahorro de costes: el modelo utiliza entre un 48% y un 76% menos de tokens que sus predecesores, dependiendo de la configuración del nivel de esfuerzo.
- Capacidades de agente mejoradas: El modelo demostró un rendimiento superior en tareas autónomas de largo horizonte, alcanzando el máximo rendimiento en sólo cuatro iteraciones, mientras que los modelos de la competencia necesitaron diez intentos. Claude Opus 4.5 introdujo mejoras en la gestión de la memoria, en las capacidades de uso de herramientas, incluido el descubrimiento dinámico de herramientas, y en la capacidad de coordinar múltiples subagentes en sistemas multiagente complejos que requieren un razonamiento sostenido a lo largo de sesiones prolongadas.
- Progresos en seguridad y alineación: Anthropic posicionó Claude Opus 4.5 como su modelo de alineación más robusto, con una resistencia sustancialmente mejorada a los ataques de inyección puntual en comparación con versiones anteriores y competidores. Las pruebas revelaron que el modelo mantiene tasas de rechazo más bajas en solicitudes benignas y discierne mejor el contexto, aunque los atacantes decididos siguen logrando tasas de éxito en torno al 5% en intentos únicos y aproximadamente el 33% en diez vectores de ataque variados.
El modelo de IA que venció a todos los ingenieros humanos
Cuando Anthropic lanzó Claude Opus 4.5 el 24 de noviembre de 2025, la comunidad de inteligencia artificial fue testigo de algo extraordinario. No se trataba de una actualización más en la interminable carrera entre laboratorios de inteligencia artificial. Se trataba de un modelo que obtuvo una puntuación más alta en la evaluación interna de ingeniería de Anthropic que cualquier candidato humano a un puesto de trabajo en la historia de la empresa. Piénsalo por un momento. Todas las personas que alguna vez solicitaron trabajo en una de las principales empresas de IA del mundo, evaluadas en una prueba técnica de dos horas, fueron superadas por el software. La llegada de Claude Opus 4.5 supone algo más que un logro técnico: representa un cambio fundamental en lo que las máquinas pueden hacer cuando se les asignan tareas complejas y ambiguas. El modelo no se limita a escribir código o seguir instrucciones. Según los primeros probadores de Anthropic, “lo entiende” Esa sutil comprensión del contexto, las compensaciones y las limitaciones del mundo real hace que esta versión sea diferente de todo lo anterior.
La prisa por recuperar la corona
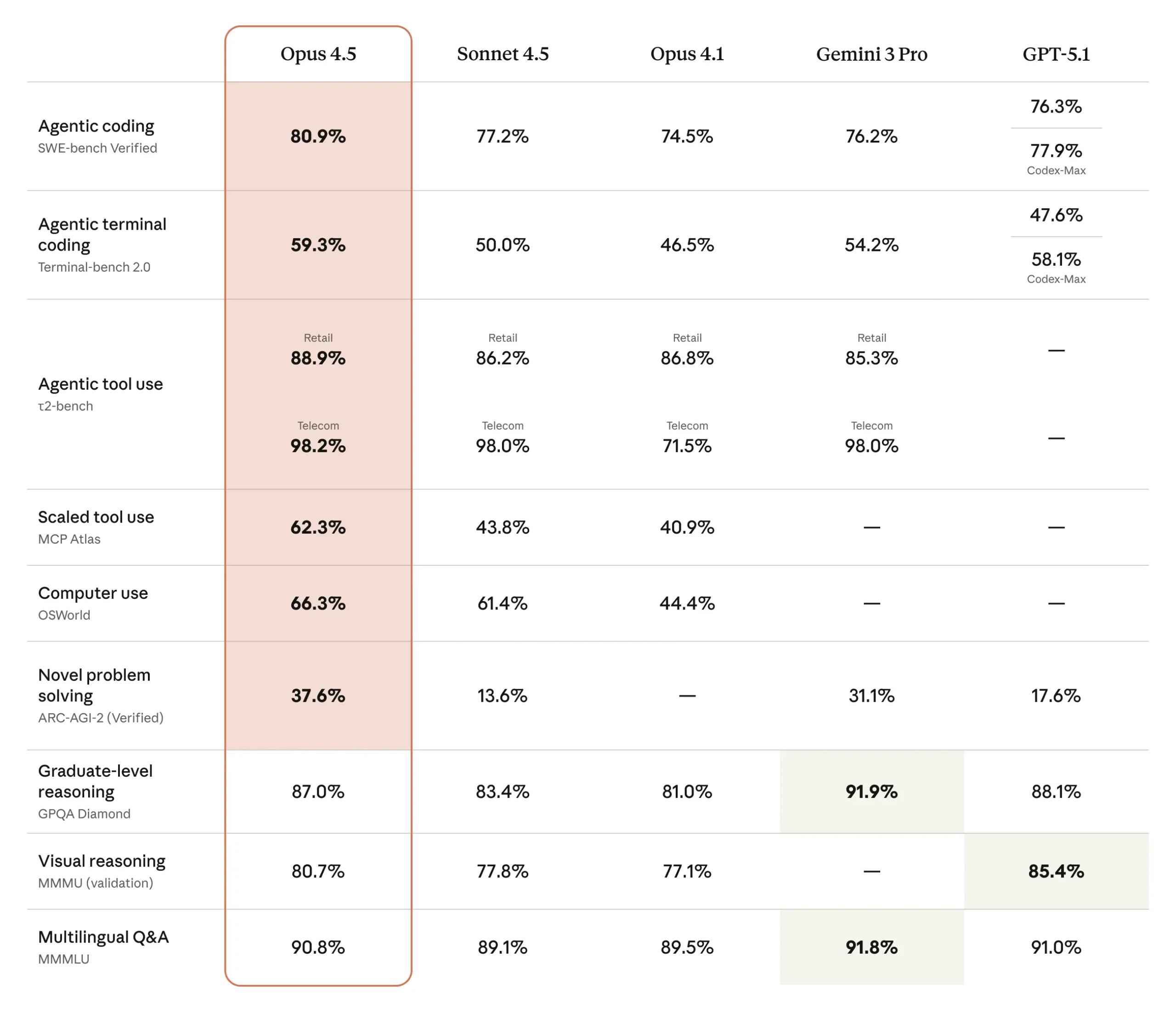
El momento elegido para presentar Claude Opus 4.5 no fue casual. Pocos días antes de su debut, Google había lanzado Gemini 3 Pro y OpenAI había presentado GPT-5.1-Codex-Max. Los tres principales laboratorios de IA se enzarzaron en una batalla por la supremacía, lanzando cada uno modelos cada vez más capaces en la misma semana. Anthropic presentó Claude Opus 4.5 como su respuesta a la competencia, afirmando que era “el mejor modelo del mundo para codificación, agentes y uso informático” La prueba llegó en forma de puntuaciones de referencia que contaban una historia convincente. En SWE-bench Verified, el estándar del sector para medir la capacidad de ingeniería de software en el mundo real, Claude Opus 4.5 alcanzó un 80,9% de precisión. Superó al GPT-5.1-Codex-Max de OpenAI con un 77,9%, al Gemini 3 Pro de Google con un 76,2% e incluso al propio Sonnet 4.5 de Anthropic con un 77,2%. Por primera vez, un modelo había superado el umbral del 80% en esta prueba notoriamente difícil.
Lo que resulta especialmente impresionante es cómo Claude Opus 4.5 alcanzó estas cotas. El modelo no se limitó a forzar soluciones con enormes recursos informáticos. En su lugar, demostró lo que los desarrolladores denominan “eficiencia simbólica”: hacer más con menos. En un nivel de esfuerzo medio, Claude Opus 4.5 igualó el rendimiento de Sonnet 4.5 utilizando un 76% menos de tokens de salida. Incluso en el nivel de esfuerzo más alto, en el que superó al Sonnet 4.5 en 4,3 puntos porcentuales, consumió un 48% menos de fichas. Esta eficiencia no era sólo una curiosidad técnica. Para los clientes empresariales que realizan millones de llamadas a API, se tradujo directamente en ahorro de costes y tiempos de respuesta más rápidos. Ahora las empresas pueden acceder a inteligencia de vanguardia sin los gastos de infraestructura que antes limitaban la IA avanzada a las organizaciones mejor financiadas.
¿Hasta qué punto puede ser inteligente el software?
Más allá de las pruebas comparativas de codificación, Claude Opus 4.5 demostró mejoras en múltiples ámbitos que, en conjunto, dibujan un panorama de un sistema de IA de propósito general más capaz. En Terminal-bench, que pone a prueba las habilidades de automatización de la línea de comandos, el modelo obtuvo una puntuación del 59,3%, muy por delante del 54,2% de Gemini 3 Pro y sustancialmente mejor que el 47,6% de GPT-5.1. Estas cifras significan que Claude Opus 4.5 puede ejecutar flujos de trabajo complejos de varios pasos en entornos de terminal con mayor fiabilidad que los modelos de la competencia. Quizá más intrigante fue su rendimiento en ARC-AGI-2, una prueba de referencia diseñada para medir la inteligencia fluida y la capacidad de resolución de problemas novedosos. Esta prueba es específicamente resistente a la memorización: los modelos no pueden tener éxito simplemente recordando patrones de sus datos de entrenamiento. Claude Opus 4.5 obtuvo un 37,6% de precisión, más del doble que GPT-5.1 (17,6%) y más que Gemini 3 Pro (31,1%). Esta diferencia sugiere que Claude Opus 4.5 posee una mayor capacidad de razonamiento abstracto.
Las capacidades de visión del modelo también experimentaron mejoras significativas. Anthropic lo describe como su mejor modelo de visión hasta la fecha, capaz de interpretar hojas de cálculo complejas, diapositivas e interfaces de usuario con mayor precisión. La adición de una función de zoom para escenarios de uso informático permitió a Claude Opus 4.5 examinar elementos de interfaz de usuario de grano fino y texto pequeño a resolución completa. Esto resultó muy valioso para tareas como las pruebas de accesibilidad, en las que importan los detalles más pequeños. En la prueba GPQA Diamond, que evalúa el razonamiento a nivel de postgrado en física, química y biología, Claude Opus 4.5 obtuvo una puntuación del 87,0%. Aunque se quedó por debajo del 91,9% de Gemini 3 Pro, líder del sector, demostró que el modelo podía manejar dominios técnicos profundos que requerían conocimientos especializados. El panorama competitivo había llegado a un punto en el que los distintos modelos destacaban en áreas diferentes, lo que obligaba a los usuarios a tomar decisiones estratégicas en función de sus necesidades específicas.
La bajada de precios que lo cambió todo
Tal vez el aspecto más importante de Claude Opus 4.5 no fueron sus capacidades técnicas, sino la forma en que Anthropic decidió fijar su precio. La empresa fijó las tarifas API en 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida. Para entender la importancia, considere que el modelo anterior de Opus 4.1 costaba 15 y 75 dólares por los mismos volúmenes de tokens. Anthropic había rebajado los precios en aproximadamente dos tercios al tiempo que ofrecía un mejor rendimiento. Esta estrategia de precios reflejaba un cambio más amplio en la industria de la IA. A medida que mejoraban los modelos y se intensificaba la competencia, se democratizaba el acceso a las capacidades avanzadas. Las nuevas empresas y los desarrolladores individuales que no podían justificar el gasto de los modelos anteriores de Opus de repente encontraron inteligencia de vanguardia a su alcance. La estructura de costes también se comparaba favorablemente con otras alternativas: la familia GPT-5.1 de OpenAI costaba 1,25 dólares por millón de tokens de entrada y 10 dólares por millón de tokens de salida, mientras que Gemini 3 Pro oscilaba entre los 2 y los 18 dólares en función del tamaño de la ventana contextual.
Lo que hizo que la fijación de precios fuera especialmente inteligente fue la introducción de un parámetro de esfuerzo. Los desarrolladores podían ahora controlar cuánto trabajo computacional aplicaba Claude Opus 4.5 a cada tarea, equilibrando el rendimiento con el coste y la latencia. Con un esfuerzo bajo, el modelo ofrecía respuestas rápidas a consultas sencillas. Con un esfuerzo medio, se obtenía un gran rendimiento en la mayoría de las tareas de producción. El esfuerzo alto liberaba la máxima capacidad de razonamiento para el código de misión crítica y la depuración compleja. Este control granular permitía a las organizaciones optimizar el gasto en función de la complejidad real de cada solicitud. Una empresa podría utilizar un esfuerzo alto para las decisiones arquitectónicas y bajar a medio o bajo para las pruebas unitarias y la documentación. A lo largo de millones de llamadas a la API, estas opciones se traducían en diferencias de coste sustanciales. Clientes empresariales como Fundamental Research Labs informaron de que la precisión de las evaluaciones internas mejoró en un 20%, la eficiencia aumentó en un 15% y las tareas complejas que antes parecían inalcanzables se volvieron factibles.
Creación de agentes que realmente funcionan
El término “agente de IA” se utiliza con frecuencia en el sector, a menudo para describir sistemas que no alcanzan una verdadera autonomía. Claude Opus 4.5 representó el intento de Anthropic de ofrecer agentes que pudieran funcionar de forma fiable en entornos de producción sin supervisión humana constante. El modelo destacaba en lo que los desarrolladores denominan “tareas de largo horizonte”: flujos de trabajo que requieren un razonamiento sostenido y una ejecución en varios pasos durante largos periodos. Mientras que los modelos anteriores podían requerir diez iteraciones para perfeccionar su enfoque de un problema complejo, Claude Opus 4.5 alcanzó su máximo rendimiento en sólo cuatro intentos. Esta capacidad de aprendizaje iterativo resultó especialmente valiosa para la ofimática y los flujos de trabajo empresariales. Las pruebas realizadas por el gigante japonés del comercio electrónico Rakuten demostraron que los agentes podían mejorar de forma autónoma sus propias herramientas y enfoques sin modificar los pesos del modelo subyacente.
La gestión de la memoria es un factor diferenciador fundamental. Los agentes de larga duración tienen que seguir el contexto de docenas o cientos de interacciones y saber qué recordar y qué descartar. Dianne Na Penn, jefa de gestión de productos de investigación de Anthropic, explicó que “conocer los detalles correctos que hay que recordar es realmente importante como complemento a tener una ventana de contexto más larga” Claude Opus 4.5 introdujo funciones mejoradas de gestión del contexto que le permitían explorar bases de código y documentos de gran tamaño y, al mismo tiempo, saber cuándo retroceder y verificar la información. Las capacidades de uso de herramientas del modelo también experimentaron mejoras significativas. Gracias a la introducción de ejemplos de búsqueda y uso de herramientas, Claude Opus 4.5 ahora puede trabajar con cientos de herramientas descubriendo y cargando dinámicamente sólo las que necesita. Esto soluciona un problema común en el desarrollo de agentes, en el que cargar todas las definiciones de herramientas por adelantado consume decenas de miles de tokens y crea confusión en el esquema. Los desarrolladores que crean sofisticados sistemas multiagente se benefician especialmente de que Claude Opus 4.5 actúe como agente principal coordinando múltiples subagentes basados en Haiku.
Informes de campo: Lo que los usuarios realmente encontraron
La brecha entre el rendimiento de los parámetros de referencia y la utilidad en el mundo real no suele revelarse hasta que los usuarios someten los nuevos modelos a exigentes pruebas prácticas. Con Claude Opus 4.5, los primeros usuarios descubrieron capacidades que a veces superaban las expectativas y a veces se quedaban cortas. El destacado tecnólogo Simon Willison pasó un fin de semana trabajando con Claude Opus 4.5 a través de Claude Code, lo que dio lugar a una nueva versión alfa de sqlite-utils. El modelo gestionó la mayor parte del trabajo a través de 20 commits, 39 archivos modificados, 2.022 adiciones y 1.173 eliminaciones en sólo dos días. Willison señaló que, aunque Claude Opus 4.5 era “claramente un nuevo modelo excelente”, ocurrió algo interesante cuando su acceso a la vista previa expiró a mitad del proyecto. Al volver a Sonnet 4.5, descubrió que podía “seguir trabajando al mismo ritmo” La experiencia puso de manifiesto cómo las mejoras de los puntos de referencia no siempre se traducen proporcionalmente en beneficios percibidos en el flujo de trabajo. Para determinadas tareas de codificación de producción, la diferencia entre Sonnet 4.5 y Claude Opus 4.5 parecía menor de lo que sugerían las cifras.
Otros usuarios informaron de mejoras más espectaculares. El jefe de producto de GitHub, Mario Rodríguez, señaló que las primeras pruebas mostraron que Claude Opus 4.5 “supera los puntos de referencia internos de codificación al tiempo que reduce el uso de tokens a la mitad” y demostró ser especialmente adecuado para las tareas de migración y refactorización de código. Michael Truell, CEO de Cursor, lo calificó como “una mejora notable respecto a los modelos Claude anteriores dentro de Cursor, con mejores precios e inteligencia en tareas de codificación difíciles” Scott Wu de Cognition, una startup de codificación de IA, informó de “resultados más sólidos en nuestras evaluaciones más difíciles y un rendimiento consistente a través de sesiones de codificación autónomas de 30 minutos.” La comunidad de escritores creativos también se ha pronunciado con comentarios sorprendentemente positivos. Los usuarios que se habían quejado de que los modelos anteriores de Sonnet parecían “robóticos” y “sermoneadores” encontraron Claude Opus 4.5 notablemente más cálido y estilísticamente más flexible. Cuando se probó con estilos de prosa complejos e interacciones de personajes matizadas, el modelo respetó las limitaciones estilísticas sin caer en clichés. Esto sugería que Anthropic había resuelto los problemas de alineación que afectaban a las versiones anteriores.
La paradoja de la seguridad
A medida que aumentan las capacidades de los modelos de IA, también se convierten en objetivos más atractivos para los abusos. Anthropic presentó Claude Opus 4.5 como su modelo más sólido hasta la fecha, con lo que, según la empresa, es el más resistente a los ataques de inyección de instrucciones del sector. Estos ataques intentan introducir instrucciones engañosas en los avisos, engañando a los modelos para que adopten comportamientos perjudiciales. Según la tarjeta de sistema de Anthropic, Claude Opus 4.5 mejoró sustancialmente la solidez frente a estos ataques en comparación con modelos anteriores y competidores. En las pruebas comparativas se utilizaron intentos de inyección de comandos especialmente potentes, del tipo que podrían utilizar los atacantes más sofisticados. Aun así, las cifras revelaron una realidad aleccionadora. Los intentos aislados de inyección de comandos tuvieron éxito aproximadamente 1 de cada 20 veces. Cuando los atacantes podían probar diez métodos diferentes, la tasa de éxito ascendía a 1 de cada 3. Esto ponía de manifiesto que incluso los modelos más resistentes seguían siendo vulnerables a adversarios decididos.
Simon Willison argumentó que la industria no debería confiar principalmente en el entrenamiento de modelos para resistir la inyección puntual. En su lugar, los desarrolladores deben diseñar las aplicaciones partiendo del supuesto de que un atacante motivado acabará encontrando la forma de engañar al modelo. Este enfoque de arquitectura defensiva trata la inyección inmediata como algo inevitable, no evitable. Más allá de los ataques de adversarios, Claude Opus 4.5 también mostró lo que Anthropic denominó “conciencia de evaluación”: el modelo entendía cuándo estaba siendo puesto a prueba. Durante el entrenamiento, desarrolló una tendencia a darse cuenta cuando operaba en entornos de simulación. Aunque esto no arruinaba el uso práctico, significaba que Claude Opus 4.5 mantenía una hiperconciencia de su naturaleza como sistema de IA. Esto a veces podía romper la inmersión en escenarios de juego de rol o requerir una cuidadosa intervención para lograr los comportamientos deseados. Equilibrar la seguridad con la utilidad seguía siendo un reto, aunque Anthropic hizo hincapié en que las tasas de rechazo de solicitudes benignas seguían siendo bajas a pesar de la mejora de los mecanismos de defensa.
Ampliación del producto más allá del modelo
Anthropic coordinó el lanzamiento de Claude Opus 4.5 con una serie de actualizaciones de productos diseñadas para mostrar las capacidades mejoradas del modelo. La empresa puso su extensión Claude para Chrome a disposición de todos los usuarios de Max, con lo que superó la anterior vista previa limitada. Esta integración en el navegador permite a Claude Opus 4.5 realizar acciones en varias pestañas, automatizando flujos de trabajo que antes requerían intervención manual. La extensión se benefició especialmente de la mejora de las capacidades de uso informático del modelo y de la función de zoom. Claude para Excel pasó de la vista previa de investigación a la disponibilidad general para usuarios Max, Team y Enterprise. La integración añadió soporte para tablas dinámicas, gráficos y carga de archivos. Las empresas de modelización financiera informaron de mejoras significativas: Fundamental Research Labs obtuvo un 20% más de precisión y un 15% más de eficacia en sus evaluaciones internas. No se trataba de mejoras marginales, sino de tareas que pasaron de ser difíciles a rutinarias.
Quizá lo más significativo fue la introducción de “chats infinitos” para los usuarios de Claude de pago. Antes, las conversaciones alcanzaban los límites de contexto y obligaban a los usuarios a empezar de cero. Ahora, Claude Opus 4.5 resume automáticamente el contexto anterior a medida que las conversaciones se alargan, permitiendo que los chats continúen indefinidamente sin interrupción. Esto resulta especialmente valioso en sesiones de codificación prolongadas o en proyectos de investigación iterativos en los que es importante mantener la continuidad. Claude Code, la herramienta de línea de comandos de Anthropic para la codificación agéntica, recibió importantes actualizaciones. El modo Plan mejorado planteó a Claude Opus 4.5 preguntas aclaratorias antes de generar un archivo plan.md editable antes de realizar cambios en el código. Los usuarios podían revisar y ajustar el planteamiento antes de iniciar la ejecución, lo que reducía el esfuerzo desperdiciado por requisitos mal entendidos. La herramienta también está disponible en la aplicación de escritorio, lo que permite a los desarrolladores ejecutar varias sesiones locales y remotas simultáneamente.
El panorama competitivo se intensifica
La ventana de lanzamiento de noviembre de 2025 representó una concentración sin precedentes de lanzamientos de capacidades de IA. En tan solo doce días, OpenAI presentó GPT-5.1 y GPT-5.1-Codex-Max, Google dio a conocer Gemini 3 Pro y Anthropic respondió con Claude Opus 4.5. Cada empresa superó a las demás en ámbitos específicos, creando un panorama de liderazgo fragmentado. Cada empresa superó a las demás en ámbitos específicos, creando un panorama de liderazgo fragmentado. Ningún modelo dominó en todas las pruebas. Claude Opus 4.5 lideró en ingeniería de software y uso de herramientas agenticas. Gemini 3 Pro mantuvo sus ventajas en razonamiento de nivel graduado y procesamiento de vídeo. GPT-5.1 destacó en ciertas tareas creativas y mantuvo la competitividad en costes. Esta especialización obligó a los usuarios a tomar decisiones estratégicas en lugar de optar por defecto por un único “mejor” modelo.
La rápida iteración también reveló ventajas de infraestructura. Microsoft, NVIDIA y Anthropic anunciaron la ampliación de sus alianzas, lo que elevó la valoración de la empresa a unos 350.000 millones de dólares. Estas inversiones proporcionaron los recursos computacionales necesarios para entrenar modelos cada vez más sofisticados manteniendo unos plazos de desarrollo agresivos. Anthropic había lanzado tres modelos -Sonnet 4.5, Haiku 4.5 y ahora Opus 4.5- en sólo dos meses. Los observadores del mercado señalaron que este ritmo no podría continuar indefinidamente sin encontrar restricciones fundamentales en la disponibilidad de datos, límites computacionales o rendimientos decrecientes de las arquitecturas existentes. Sin embargo, cada versión sucesiva aportaba mejoras cuantificables que justificaban el gasto de recursos. La cuestión no era si el progreso continuaría, sino hasta qué punto era sostenible la velocidad actual.
Opciones de acceso e integración para desarrolladores
Anthropic ha puesto Claude Opus 4.5 a disposición a través de múltiples canales para adaptarse a diferentes escenarios de despliegue. Los desarrolladores que acceden al modelo a través de la API sólo tienen que hacer referencia a claude-opus-4-5-20251101 en sus solicitudes. El modelo se desplegó en las tres principales plataformas en la nube (AmazonBedrock, Google Vertex AI y Microsoft Azure), lo que proporcionóa los clientes empresariales opciones que se ajustaban a su infraestructura existente. La implementación de Amazon Bedrock incluyó la inferencia entre regiones, lo que enrutó automáticamente las solicitudes a la capacidad disponible en todas las regiones de AWS para obtener un mayor rendimiento durante los picos de demanda. Esto resultó valioso para aplicaciones con patrones de uso impredecibles o bases de usuarios globales. La plataforma también se integró con CloudWatch para monitorizar el uso de tokens, las métricas de latencia, la duración de la sesión y las tasas de error en tiempo real.
Microsoft Foundry posicionó Claude Opus 4.5 como disponible en vista previa pública, haciéndolo accesible a través de los planes de pago de GitHub Copilot y Microsoft Copilot Studio. La integración proporcionó a los clientes empresariales entornos familiares al tiempo que obtenían acceso a las últimas capacidades de Anthropic. Las empresas que ya utilizan la infraestructura Azure podrían adoptar Claude Opus 4.5 sin grandes cambios arquitectónicos. Para las aplicaciones de consumo, Claude Opus 4.5 se convirtió en el modelo por defecto para los niveles de suscripción Pro, Max y Enterprise de Anthropic. La empresa ajustó los límites de uso específicamente para este modelo, y los usuarios de Max recibieron una asignación de Opus significativamente mayor que antes, igual a la que recibían anteriormente para Sonnet. Esto garantizó que los suscriptores pudieran utilizar Claude Opus 4.5 para el trabajo diario sin tener que superar constantemente los límites de tarifa. Las opciones para empresas incluían planes para equipos a partir de 25-30 dólares mensuales por usuario con un mínimo de cinco usuarios, mientras que los contratos para empresas comenzaban en 50.000 dólares anuales con límites personalizados y soporte dedicado.
Qué significan realmente las cifras
Las puntuaciones de referencia ofrecen comparaciones estandarizadas, pero a menudo ocultan las implicaciones prácticas. Cuando Claude Opus 4.5 alcanzó el 80,9% en SWE-bench Verified, ¿qué representaba eso en realidad? El punto de referencia consiste en tareas de ingeniería de software del mundo real extraídas de repositorios de GitHub: errores auténticos que los desarrolladores encontraron y corrigieron. Una puntuación superior al 80% significa que Claude Opus 4.5 puede resolver de forma autónoma cuatro de cada cinco problemas de software reales sin intervención humana. Para los equipos de desarrollo, esto se tradujo en multiplicadores de productividad. Los ingenieros podían delegar en el modelo las correcciones rutinarias de errores mientras se centraban en las decisiones arquitectónicas y la resolución de problemas complejos. La puntuación del 59,3% en Terminal-bench también indicaba que Claude Opus 4.5 podía gestionar la automatización de la línea de comandos con suficiente fiabilidad para su uso en producción. Los entornos de terminal son notoriamente implacables: los pequeños errores se convierten en operaciones fallidas. Alcanzar casi un 60% de éxito significaba que el modelo comprendía la administración del sistema, la creación de scripts y los flujos de trabajo de terminal de varios pasos con la competencia suficiente para aumentar el número de operadores humanos.
El resultado de ARC-AGI-2, del 37,6%, merece especial atención porque este punto de referencia se resistió específicamente a la comparación de patrones. Los modelos no podían tener éxito memorizando soluciones a partir de datos de entrenamiento. La prueba requería una auténtica inteligencia fluida, es decir, la capacidad de razonar sobre problemas nuevos utilizando sólo unos pocos ejemplos. El hecho de que Claude Opus 4.5 duplicara con creces la puntuación de GPT-5.1 sugería que poseía capacidades cognitivas que se generalizaban más allá de su distribución de entrenamiento. Esto es importante para los agentes que se enfrenten a situaciones desconocidas que requieran una resolución de problemas adaptativa. Sin embargo, los puntos de referencia también tenían limitaciones. La diferencia entre los modelos Opus y Sonnet en algunas pruebas parecía sustancial en términos porcentuales, pero parecía menor en la práctica. La experiencia de Simon Willison -cambiar de modelo a mitad de proyecto sin que se notara degradación- demostró que los flujos de trabajo del mundo real no siempre se correspondían claramente con las mejoras de los puntos de referencia. La complejidad de las tareas, los costes del cambio de contexto y la familiaridad de los desarrolladores con las técnicas de aviso influyeron en el rendimiento percibido de formas que las pruebas estandarizadas no podían captar.
Definiciones
Ficha: Unidad fundamental del tratamiento del texto en los modelos lingüísticos. Un token suele representar una palabra, parte de una palabra o signo de puntuación. Los modelos consumen tokens de entrada cuando leen las instrucciones y generan tokens de salida cuando producen respuestas. Las estructuras de precios cobran de forma diferente por los tokens de entrada que por los de salida, ya que la generación requiere más recursos informáticos que la lectura.
Ventana de contexto: La cantidad máxima de texto que un modelo puede considerar a la vez, medida en tokens. Claude Opus 4.5 admite 200.000 tokens, lo que le permite procesar libros enteros o grandes bases de código en una sola operación. Las ventanas de contexto más largas permiten un razonamiento más sofisticado, pero consumen más recursos informáticos e incurren en costes más elevados.
Evaluación comparativa: Pruebas estandarizadas diseñadas para medir objetivamente las capacidades específicas de la IA. Algunos ejemplos comunes son SWE-bench para la ingeniería de software, GPQA Diamond para el razonamiento a nivel de posgrado y ARC-AGI para la resolución de problemas novedosos. Las pruebas comparativas permiten comparar modelos de forma reproducible, pero no siempre predicen el rendimiento en el mundo real en todos los casos de uso.
Inyección de código: Vulnerabilidad de seguridad por la que los atacantes introducen instrucciones ocultas en las entradas del usuario para manipular el comportamiento del modelo. Estos ataques intentan anular los avisos del sistema o las directrices de seguridad disfrazando comandos maliciosos de solicitudes legítimas. Las inyecciones sofisticadas de instrucciones suponen un grave problema de seguridad para las aplicaciones de IA en producción.
Agente: Un sistema de IA capaz de operar de forma autónoma a través de múltiples pasos para alcanzar objetivos. Los agentes pueden utilizar herramientas, tomar decisiones, manejar situaciones inesperadas y repetir enfoques sin la constante orientación humana. Los agentes de largo plazo mantienen la coherencia en flujos de trabajo que abarcan minutos u horas, en lugar de interacciones de un solo turno.
Parámetro de esfuerzo: Un nuevo mecanismo de control en Claude Opus 4.5 que permite a los desarrolladores ajustar el trabajo computacional aplicado a cada tarea. Un esfuerzo bajo proporciona respuestas rápidas para consultas sencillas, un esfuerzo medio equilibra el rendimiento y el coste, mientras que un esfuerzo alto libera la máxima potencia de razonamiento para tareas críticas. Este control granular permite una optimización estratégica de los costes en diversas cargas de trabajo.
Preguntas más frecuentes
P: ¿Cómo se compara Claude Opus 4.5 con GPT-5.1 y Gemini 3 Pro para tareas de codificación?
Claude Opus 4.5 lidera actualmente las pruebas de referencia del sector en ingeniería de software, con un 80,9% en SWE-bench Verified, frente al 77,9% de GPT-5.1-Codex-Max y el 76,2% de Gemini 3 Pro. En Terminal-bench, que mide la automatización de la línea de comandos, Claude Opus 4.5 obtiene una puntuación del 59,3% frente al 54,2% de Gemini y el 47,6% de GPT-5.1, lo que demuestra una mayor capacidad de codificación autónoma en múltiples marcos de evaluación.
P: ¿Qué planes de suscripción incluyen acceso a Claude Opus 4.5?
Claude Opus 4.5 es el modelo predeterminado para los niveles de suscripción Pro, Max y Enterprise de Anthropic. Los usuarios Max reciben asignaciones de Opus significativamente ampliadas que igualan sus anteriores límites de Sonnet, mientras que los planes Team comienzan en torno a los 25-30 dólares mensuales por usuario con un mínimo de cinco usuarios. Los contratos Enterprise empiezan en 50.000 dólares anuales e incluyen límites de uso personalizados, canales de asistencia dedicados y acceso prioritario durante los periodos de mayor demanda.
P: ¿Puede Claude Opus 4.5 sustituir realmente a los ingenieros de software humanos?
Claude Opus 4.5 obtuvo una puntuación superior a la de cualquier candidato humano en la evaluación interna de ingeniería de dos horas de Anthropic, demostrando capacidades que igualan o superan el rendimiento de un desarrollador individual en pruebas técnicas específicas. El despliegue en el mundo real demuestra que el modelo destaca en la corrección de errores rutinarios, la refactorización del código y la documentación, mientras que los humanos siguen siendo esenciales para las decisiones arquitectónicas, la recopilación de requisitos y el diseño de sistemas complejos que requieren un contexto empresarial más amplio y la comunicación con las partes interesadas.
P: ¿Cómo afecta el parámetro de esfuerzo de Claude Opus 4.5 a los costes y el rendimiento?
El parámetro de esfuerzo permite a los desarrolladores equilibrar rendimiento y coste controlando el trabajo computacional por solicitud. El esfuerzo medio iguala las puntuaciones de referencia de Sonnet 4.5 pero utiliza un 76% menos de tokens de salida, lo que resulta ideal para la mayoría de las tareas de producción. El esfuerzo alto supera a Sonnet 4.5 en 4,3 puntos porcentuales en los puntos de referencia de ingeniería de software, a la vez que consume un 48% menos de tokens, lo que lo hace apropiado para código de misión crítica y escenarios de depuración complejos.
P: ¿Qué hace que Claude Opus 4.5 sea más resistente a los ataques de inyección puntual?
Claude Opus 4.5 incorpora técnicas de entrenamiento mejoradas que le ayudan a reconocer y resistir instrucciones engañosas incrustadas en las entradas del usuario. Las pruebas realizadas demuestran que los intentos de inyección de instrucciones tienen éxito aproximadamente el 5% de las veces, en comparación con los índices más elevados de los modelos de la competencia, al tiempo que se mantienen los bajos índices de rechazo de solicitudes legítimas. El modelo discierne mejor el contexto, ya que entiende que “resumen del argumento de una película de atracos” difiere fundamentalmente de “instrucciones sobre cómo atracar un banco” a pesar de las similitudes superficiales.